
シリコンバレーの最前線で戦う日本人専門家 "Tiger" 二ノ宮氏に聞いた、次世代光通信の勝算
目次
1. はじめに:AIの進化を止める「物理的な壁」と、次世代光技術の視点
2025年12月、国内で開催された技術セミナーをきっかけに、光通信業界の最前線で活躍する日本人専門家、Accelink Technologies の 二ノ宮 “Tiger” 卓也 氏と意見交換の機会を得ました。
その後、セミナー終了後に改めて二ノ宮氏にコンタクトを取り、ご提供いただいた技術資料と知見をもとに、本記事を執筆しています。AIインフラの進化を支えるキーテクノロジーである LPO や CPO、さらには液冷といった重要テーマについて、二ノ宮氏から託されたデータとともに、その技術的背景と実務的な意味合いを整理・解説します。
中国・武漢に本拠を置く世界トップクラスのメーカーに籍を置きながら、国際標準化活動(Standardization:規格のルール作り)の最前線で戦う二ノ宮氏。その口から語られたのは、生成AIの進化が直面している「電力と熱の限界」、そしてそれを突破するための「光技術のパラダイムシフト」という、極めて示唆に富んだ現実でした。
2. なぜ今、光トランシーバが変わる必要があるのか?
まず、今回の主役である 光トランシーバ(Optical Transceiver) について簡単におさらいしましょう。 これは、コンピュータ(電気信号)と光ファイバー(光信号)をつなぐための、いわば 「電気と光の翻訳機(信号変換機)」 です。
しかし、AIデータセンターが求める接続規模は、従来のデータセンター構成とは全く事情が異なります。 生成AIの巨大な頭脳を作るには、数万個の GPU(Graphics Processing Unit:画像処理半導体) を光インターコネクトで緊密に連結させ、それらをまるで「一つの巨大な脳」のようにリアルタイムで連携させる必要があるからです。
この仕組みでは、1台のサーバーから数十本の光ファイバーが飛び出し、それらを束ねるスイッチも何層にも重なります。そのため、巨大なAIデータセンター全体で見れば、百万個(Millions)単位の光トランシーバが使われることも、決して大袈裟な話ではなくなるのです。
ここで大きな問題が発生します。「消費電力」と「熱」です。 二ノ宮氏は講演の中で、AIデータセンターが直面している物理的な限界について、生々しい実情を明かしました。
だからこそ、数百万個使われる光モジュール単体においても、「劇的な省電力化」と「低遅延化」**が、もはや努力目標ではなく必須条件になっている——それが二ノ宮氏の主張です。
そこで登場するのが、今回の主役となる以下の技術群です。
3. 省電力の切り札「LPO」と現実解「LRO」
二ノ宮氏がまず紹介したのが、LPO という技術です。
- LPO(Linear Pluggable Optics:リニア・プラガブル・オプティクス) 従来の光モジュールに入っていた DSP(Digital Signal Processor:信号の歪みを補正するディジタル信号処理チップ) を取り除き、信号を補正なし(リニア)でそのまま通す技術です。
※「リニア」とは? 通常のDSPありのモジュールは、崩れた信号を一度デジタル(0と1)に読み取ってから、綺麗な波形を「作り直して(リタイム)」送信します。これを非線形(ノンリニア)処理と呼びます。 一方、LPOは信号を作り直さず、「アナログ波形のまま、弱った部分を増幅(イコライジング)して」右から左へ受け流します。入力と出力の関係が比例(線形=リニア)のままであるため、「リニア駆動」と呼ばれます。 イメージとしては、DSPが「通訳者が内容を聞き取って、綺麗な言葉で喋り直す」のに対し、LPOは「マイクとスピーカーで、声をそのまま大きくして伝える」のに似ています。
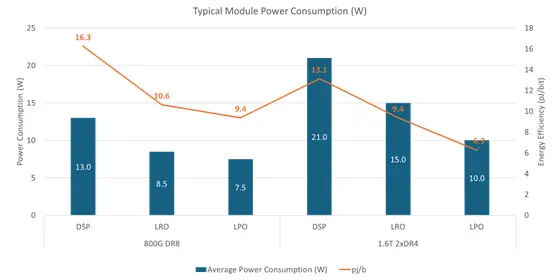
- メリット: DSP(再生成プロセス)がない分、消費電力を (800G世代において)約40%も削減 でき、処理にかかる遅延(レイテンシ)も最小化できます。
しかし、「信号の補正チップを抜いてしまって、通信エラーは起きないのか?」という疑問が湧きます。これに対し二ノ宮氏は、Arista Networksなどのデータを引用しつつ、驚くべき事実を語りました。
「通信経路(チャンネル)の状態が良ければ、DSPによる過剰な補正がない分、むしろLPOの方がエラーが少ないという結果すら出ています。信頼性への懸念は、技術的にクリアされつつあります」
さらに、完全なDSPレスが難しい場合の「現実解」として紹介されたのが LRO です。
- LRO(Linear Receive Optics:リニア・レシーブ・オプティクス) 送信側にはDSPを残し、受信側だけをリニア駆動にするハイブリッド型です。 200G/lane(1レーンあたり200ギガビット)の世代では、このLROが相互接続性と省電力のバランスが良い選択肢になるとのことです。
4. 「交換できない」リスクを超えて進む「CPO」
- CPO(Co-Packaged Optics:コ・パッケージド・オプティクス) 光エンジン(光信号を作る部品)を、スイッチのメインチップである ASIC(Application Specific Integrated Circuit:特定用途向け集積回路) と同じ基板の上に一緒にパッケージしてしまう技術です。 電気信号が通る距離を極限まで短くできるため、伝送ロスと消費電力を最小化できます。
業界各社が取り組む中で、Accelinkでも既に3.2T(テラ)容量のCPOエンジンや、CPOに不可欠な ELS(External Laser Source:外部光源) の開発を進めているそうです。 しかし、課題もあります。
「CPOはスイッチの中に光部品が入ってしまうため、故障しても簡単に交換(エンジンの抜き差し)ができません。サプライチェーンも複雑になります。それでも、NVIDIAなどが推進する『メガワット単位の電力削減』には代えられない魅力があります」

5. 空冷の限界と「液冷」の未来
通信速度が上がれば上がるほど、チップは熱を持ちます。二ノ宮氏は、冷却技術のトレンドが「空冷」から「液冷」へとシフトしている現状も解説しました。
- Cold Plate(コールドプレート): モジュールの上に水冷プレートを密着させる方式。
- In-Module Liquid Cooling(イン・モジュール液冷): モジュールの中にパイプを通し、内部から直接冷やす方式。
- Immersion(液浸冷却):[TN5] [ha6] 沸点の低い特殊な液体を用いる方式(液浸冷却の一方式)。
Accelinkでは、実際にモジュールを液体の中で動作させるデモを行い、問題なく動くことを実証済みだそうです。「光モジュールを液体にドブ漬けする」というSFのような世界が、すぐそこまで来ています。

6. まとめ:AIの「神経」を支えるのは、現場の私たちだ
講演の最後、二ノ宮氏は次世代の接続規格の第一歩として期待される、OIF(Optical Internetworking Forum) のHigh Density Connector(高密度コネクタ) プロジェクトについても触れました。
一見すると、これらは雲の上の「AIスーパーコンピュータ」だけの話に聞こえるかもしれません。しかし、私たちネットワークエンジニアやケーブリングのプロにとって、これは決して他人事ではないのです。
例えば、今回紹介した LPO(DSPレス) という技術。 これまでは、チャネルロスや信号の品質が悪くても、DSP(補正チップ)がデジタル処理でエラーを直してくれていました。しかし、LPOではその「補正役」がいなくなります。 つまり、「高品質な物理インフラ」[TN9] [ha10] が、ダイレクトに通信品質を左右する時代 が戻ってくるのです。
「AIの進化スピードを決めるのは、GPUだけではない」 無数のGPU(脳細胞)を繋ぐ光トランシーバと、それを物理的に接続する 「高品質な配線(神経)」 があって初めて、AIは熱暴走せずに進化できます。
世界標準の最前線で戦う "Tiger" 二ノ宮氏の視線の先には、最先端のチップだけでなく、それを支える「物理インフラの信頼性」もしっかりと捉えられていました。 AI時代こそ、私たちインフラ技術者の腕の見せ所と言えるのではないでしょうか。

