

※本記事は、パンドウイットコーポレーション日本支社様のご協力により、プレゼン資料「Structured Cabling for AI Data Centers」をもとに、Cabling Cert Techが編集・作成したものです。
AI(人工知能)の進化は、データセンターのインフラに大きな変革をもたらしています。従来のDC(データセンター)とは異なり、AI DCは超高密度な配線と膨大な電力を必要とします。このような特殊な環境でAIの性能を最大限に引き出すには、構造化ケーブリング(整理された計画的な配線システム)が不可欠です。本記事では、AI DCでなぜ構造化ケーブリングが必要なのか、そしてそれがどのように作業の効率と将来の拡張性を向上させるのかを、データ・センター管理者、配線工事業者やネットワークエンジニアの皆さんの視点から詳しく解説します。
目次
はじめに:AI DCの用語ミニ解説
AI DCの資料には、しばしば専門用語が登場します。まず、これらの基本的な用語を押さえておきましょう。
- Day0 / Day1 / Day2:
- Day0: 企画、設計、調達の段階です。
- Day1: 初期導入と構築の段階です。
- Day2: 運用開始後の拡張や保守の段階です。AI DCでは、Day2での拡張(Phased Scaling)が頻繁に行われます。
- スパイン(Spine) / リーフ(Leaf):
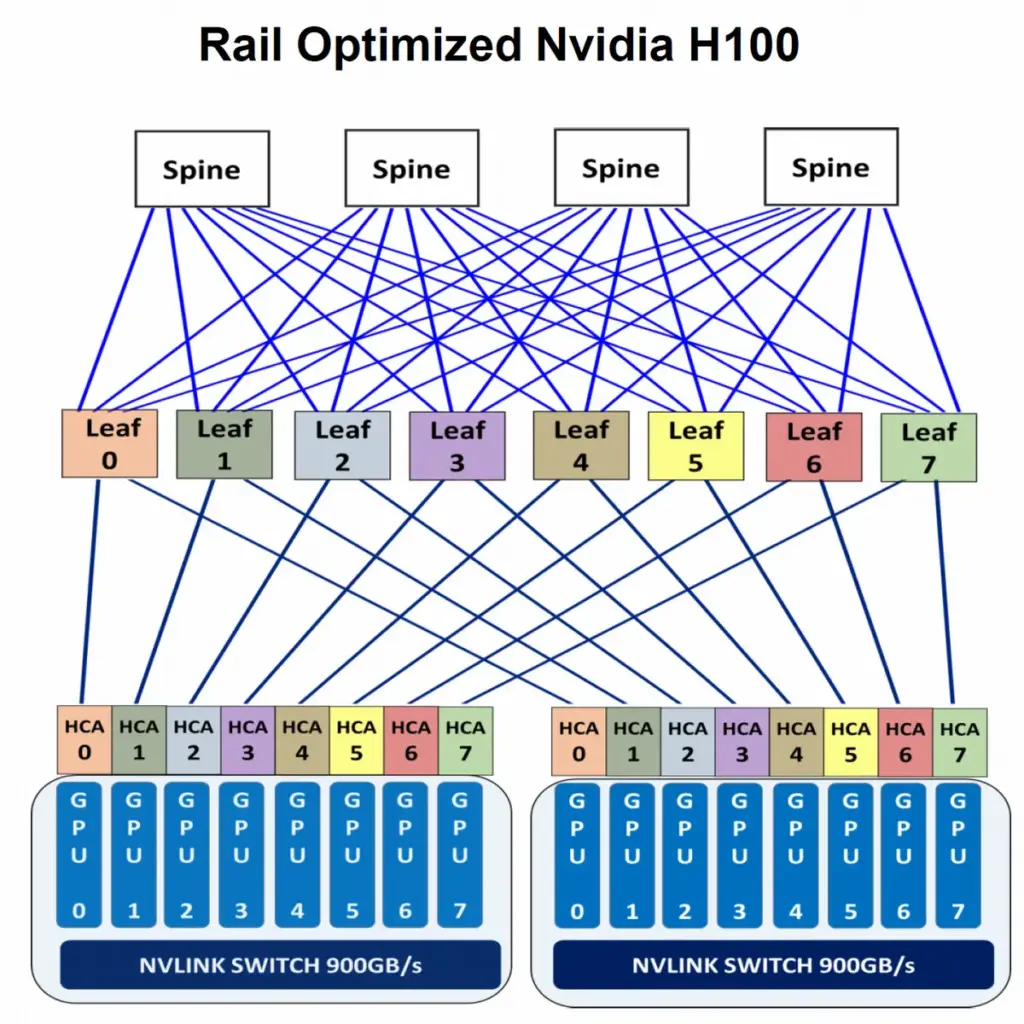
- ネットワークの「幹と枝」の関係を表します。各ラックにあるLeaf(枝)スイッチが、上位のSpine(幹)にフルメッシュで接続されるアーキテクチャです。AIではGPU間のホップ数(ネットワーク機器を通過する回数)を最小化する設計が重要です。
1. 従来のDCとAI DCの決定的な違い
AI DCの設計と配線は、従来のDCとは根本的に異なります。この違いを理解することが、AI DCにおけるケーブリングの重要性を把握する第一歩です。
| 項目 | AIデータセンター | ハイパースケールDC | エンタープライズDC |
| 電力/ラック | 40-120 kW | 10-20 kW | 5-15 kW |
| 冷却 | 液冷/RDHX/チップ直冷など | 空冷+一部液冷 | 主に空冷 |
| 配線/コネクタ | MPO(BASE-8中心)+LC、マルチ/シングルモード混在 | LC中心 | LC中心 |
| スイッチ速度 | 800G | 400-800G | 25-100G |
| プロトコル | InfiniBand / Ethernet | Ethernet中心 | Ethernet中心 |
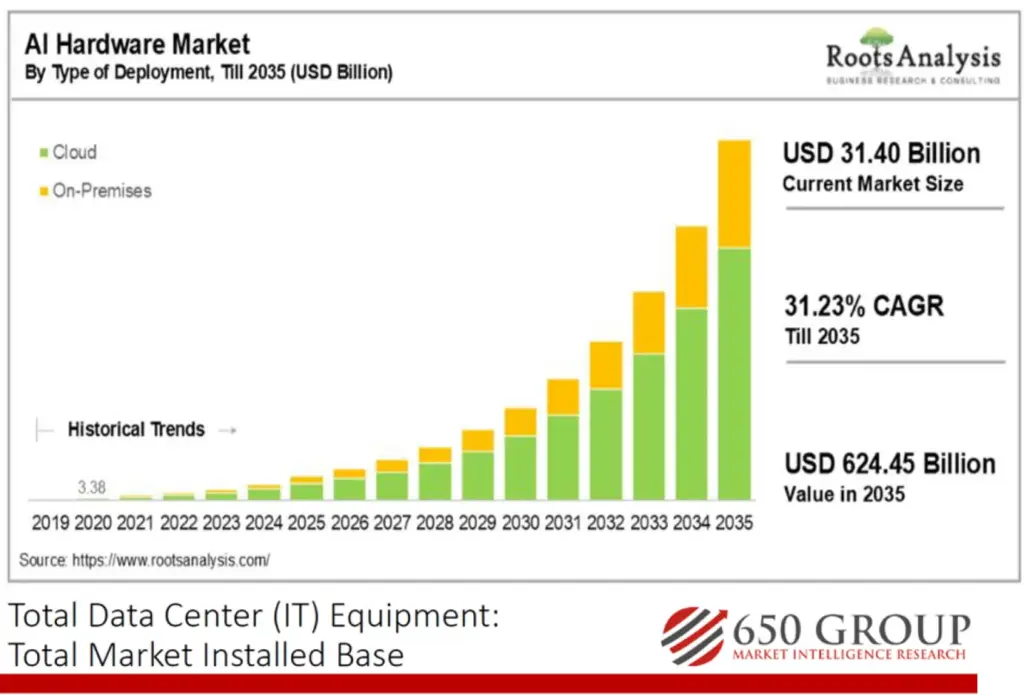
AIは、高電力・高密度・低遅延が特徴です。とりわけGPU(グラフィックス処理装置)間の高速通信が必須で、したがってケーブルも高速かつ大量に要します。その結果、AIネットワークラックには6,000本以上のファイバーが集中する場合があります。加えて市場面でも拡大が続いており、AIハードウェア市場は2035年までにCAGR 31.23%で成長し、6,244.5億ドル(約92兆円)に達すると予測されています。
2. 直接配線方式が抱える課題
構造化ケーブリングではない、直接ケーブルを接続する方式(Direct Cabling)には、AI DCのような環境においていくつかの大きな欠点があります。
a. Day1での複雑さと非効率性
直接配線では、サーバーラックとネットワークラックを個別にケーブルで接続する必要があり、ラックの設置時に大量のケーブルを一つずつ敷設しなければなりません。これにより、作業が複雑になり、設置に多くの時間と労力がかかります。

b. Day2での再配線負荷
AIシステムのDay2(運用開始後の拡張)では、新しいAI Pod(AI計算単位)を追加するたびに、既存のスパインスイッチに接続されたケーブルの約50%を新しいスパインへ差し替える作業が発生します 。この「50%リプラグ」作業は、手作業で行うと膨大な時間と人件費を要します。直接配線の場合、
コンテンツの続きに進むには、以下のフォームにご入力ください。
3. 構造化ケーブリングがもたらす4つの価値
構造化ケーブリングは、これらの課題を解決し、作業性、効率性、そして将来的な拡張性を飛躍的に高めます。
a. インストールとトラブルシューティングの効率化
構造化ケーブリングでは、Day1でトランクケーブル(複数のファイバーを束ねたケーブル)をあらかじめ敷設しておけます。ラックが到着した後は、パッチコード(機器を接続する短いケーブル)を差し込むだけで済み、設置時間を大幅に短縮できます。これにより、トラブルシューティングも容易になります。
b. 配線スペースの劇的な削減
個別ケーブルを大量に敷設するのではなく、複数のファイバーをトランクに集約することで、配線経路のスペースを最大で70%削減できます。これにより、ケーブルが密集することによるエアフロー(空気の流れ)の悪化を防ぎ、適切な曲げ半径を確保し、効率的な冷却を維持できます。

c. 将来的な拡張の簡素化
構造化ケーブリングは、Day2での「50%リプラグ」のような大規模な再配線作業を簡素化します。Day1で敷設したトランクケーブルはそのままに、短尺のパッチコードを差し替えるだけで済む設計が可能です。
d. 性能への悪影響なし
AIネットワークはレイテンシ(遅延)が非常に重要ですが、構造化ケーブリングはレイテンシに悪影響を与えません。むしろ、Shuffle Box(シャッフルボックス)のようなソリューションを使うことで、ネットワークの階層を減らし、ホップ数(ネットワーク機器を通過する回数)を最小限に抑え、より低遅延なネットワークを実現します。
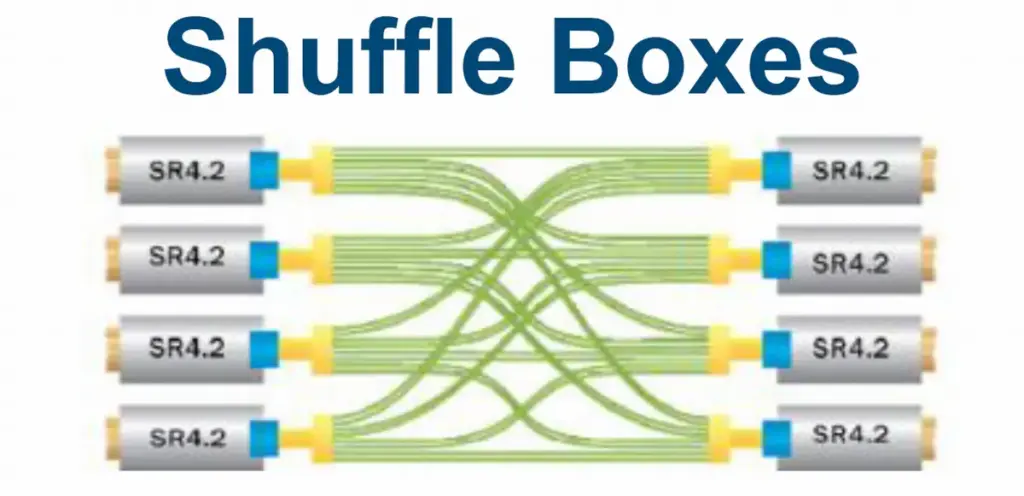
4. 現場で役立つ実践的ソリューション
AI DCの複雑な配線を効率的に進めるために、現場で役立つ具体的なソリューションと製品をいくつかご紹介します。
a. 配線と管理の最適化
- MPOコネクタ: 800Gの高速通信には、MPOコネクタ(複数のファイバーを一本のコネクタで接続する)が主流です。特にAI DCでは、8ファイバーのMPOが中心的に使われています。
- 高密度パネル: 1RU(ラックユニット)に32ポートや64ポートのMPOアダプターを収容できる高密度パネルは、ラックの前面スペースを効率的に利用し、ケーブルの密集を防ぎます。
- 28AWGパッチコード: OOBM(Out-of-Band Management:管理の冗長性を確保するネットワーク)には、従来の24AWGよりも細い28AWGの銅線パッチコードを使用することで、ラック前面のケーブル占有スペースが小さくなり、より良いエアフローとポートの視認性を確保できます。
b. ドキュメンテーションの自動化
AI DCの配線は膨大で、手作業でのラベリングやドキュメント作成は非効率でミスが発生しやすい作業です。PanduitのRapidID™ Network Mapping Systemは、ケーブルの接続をスキャンして自動でドキュメント化するシステムです。これにより、現地での手作業を排除し、人為的なミスを減らすだけでなく、作業時間を最大50%短縮できます。
c. Pod規模別の必要ファイバー数と作業モデル
AI Pod(AI計算を実行するサーバー群とネットワーク機器の集合体)の規模が大きくなると、必要となるファイバーの総数も劇的に増加します。以下に、規模別の総ファイバー本数の例を示します 32。
| AI Pods | GPU数 | 総ファイバー本数 |
| 1 | 256 | 699 |
| 8 | 2048 | 6,144 |
| 32 | 8192 | 24,576 |
| 64 | 16384 | 49,152 |
5. 将来の展望とまとめ
AIの進化に伴い、ネットワーク速度も800Gから1.6Tへと向かう動きがあります。将来のアップグレードに備えるためには、最初からBASE-8を中心としたモジュール化や、PanMPO(工具を使わずに極性やジェンダーを簡単に変更できるコネクタ)のような柔軟性の高い製品を採用することが重要です。

AIデータセンターの構築は、配線工事業者やネットワークエンジニアにとって、技術革新とビジネスチャンスに満ちた分野です。本記事が、皆さんのスキルアップと将来のプロジェクトの一助となれば幸いです。

